Řešil jsem nyní na projektu uložení a práci se stromovou strukturou dat. 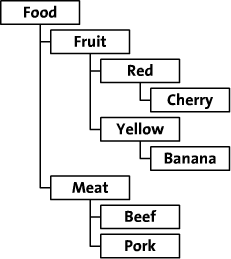
Každého asi napadne řešení, kdy objekt si bude držet referenci na svého předka. Toto řešení je funkční, ale má jednu velkou nevýhodu a tou je pomalost načítání stromu. To je dáno rekurzivním algoritmem a tedy velkým množstvím dotazů do databáze. Na druhou stranu je velice jednoduché přidávat nové objekty nebo je přesouvat. Tento model se označuje jako The Adjacency List Model.
Já jsem ale potřeboval "opačné řešení" - co nejrychlejší načítání stromu i za cenu toho, že při správě stromu si uživatel chvíli počká. Pro tento případ je ideální tzv. Modified Preorder Tree Traversal algoritmus. Ten si kromě odkazu na svého předchůdce eviduje další dvě pomocné hodnoty, tak aby sestavení stromu bylo co nejrychlejší. Naopak změny v hierarchii stromu mohou vést k nutnosti přepočítat pomocné hodnoty u všech objektů.
Více informací k uvedené problematice lze nalézt zde:
- Storing Hierarchical Data in a Database
- článek na Intervalu - Metody ukládání stromových dat v relačních databázích
- Wikipedia - Tree traversal



4 komentáře:
Pro mě by bylo přímočařejším řešením si tam přidat rovnou předpočítanou položku s "cestou" tj.
#0 "Food" "/Food"
#1 "Fruit" "/Food/Fruit"
#2 "Red" "/Food/Fruit/Red"
...
Strom se udělá seřazením podle "cesty". Možná bych tam neukládal názvy položek ale rovnou ID (primární klíč?) a tím by se elegantně vyřešil problém s přejmenováním položek, ale zase by to nešlo tak hezky seřadit jako když jsou tam rovnou ty texty ...
V tomto návrhu vidím jednu nevýhodu - špatně se budou přesouvat jednotlivé objekty, špatně se budou vkládat nové objekty. Chybí mi tam prostě flexibilita...
Ukladani levych a pravych ohodnoceni je sice pekne co se tyce vyberu podstromu (vychazi na jeden select). Ale pridavani dalsiho nodu je bohuzel prilis komplikovane. Osobne davam prednost algoritmu, kdy mate dve tabulky - struktura nodu (obycejna sebereference) a struktura podstromu, kde se ulozi node a jeho root. Tento algoritmus sice prinasi dalsi tabulku - ktera neni v zaveru vyrazne velka, ale navic oproti ohodnoceni nodu neprovadi pri vkladani zadne prepocitavani a vyber podstromu (select) je take jednoduchy. Odkaz na implementaci: http://www.codeproject.com/KB/database/Trees_in_SQL_databases.aspx
Jeste par odkazu:
http://dev.mysql.com/tech-resources/articles/hierarchical-data.html
http://www.openwin.org/mike/books/index.php/trees-and-hierarchies-in-sql
Okomentovat